Generations
Non-determinstic functions that require evaluation.
When you mark a function with the generation decorator, you are telling Lilypad that the decorated function is powered by a Large Language Model (LLM).
This ensures that the function is automatically versioned, and any call the function is traced against the version.
import lilypad
from openai import OpenAI
client = OpenAI()
@lilypad.generation()
def answer_question(question: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": question}],
)
return str(completion.choices[0].message.content)
if __name__ == "__main__":
lilypad.configure()
answer = answer_question("What is the meaning of life?")
print(answer)In the above example, answer_question will be versioned and traced when called.
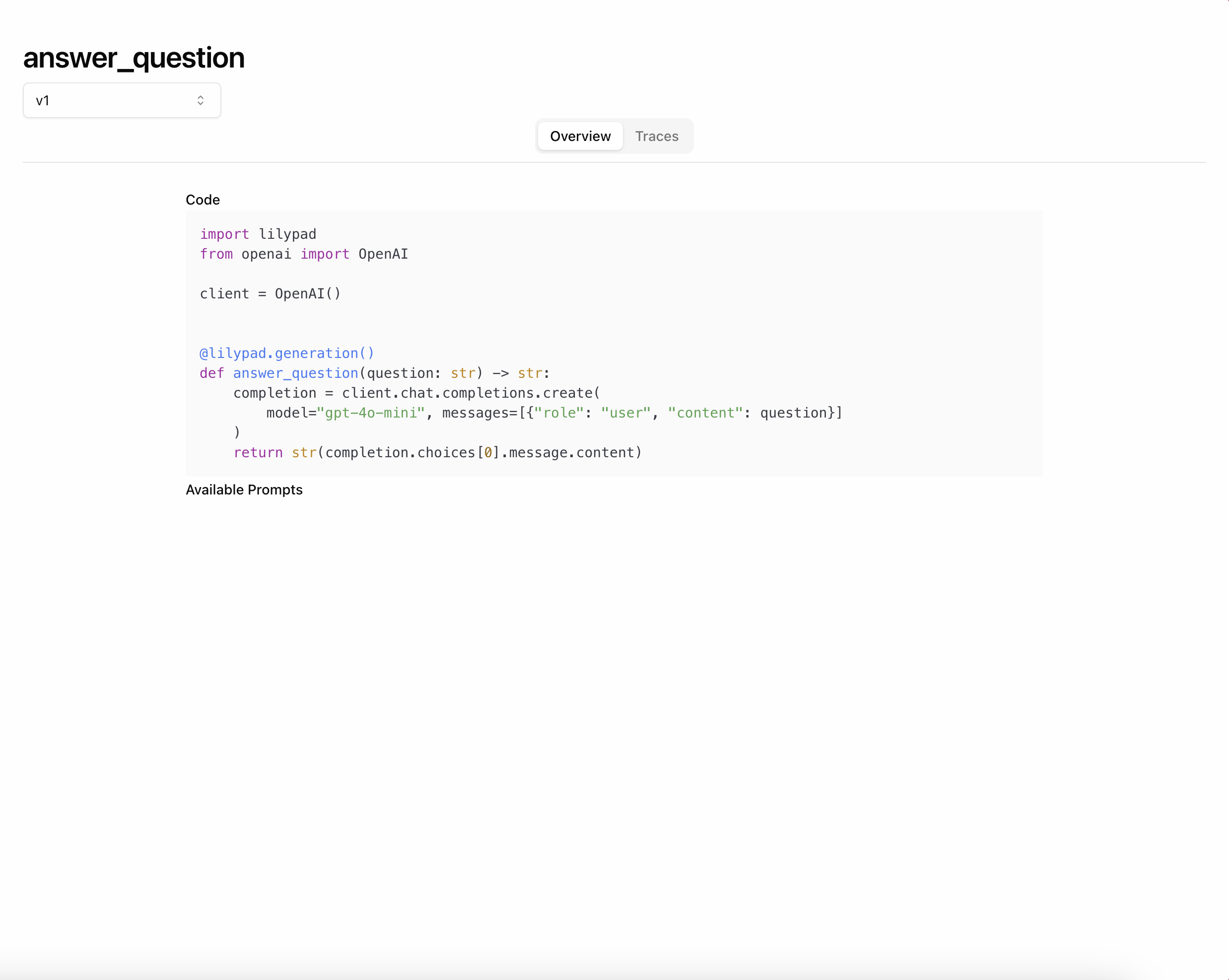
View this generation by navigating to Generations and clicking on the
answer_question card.
If you change anything inside of answer_question, that will change the version.
For example, if you change the model from gpt-4o-mini to gpt-4o, that will create
a new version of answer_question.
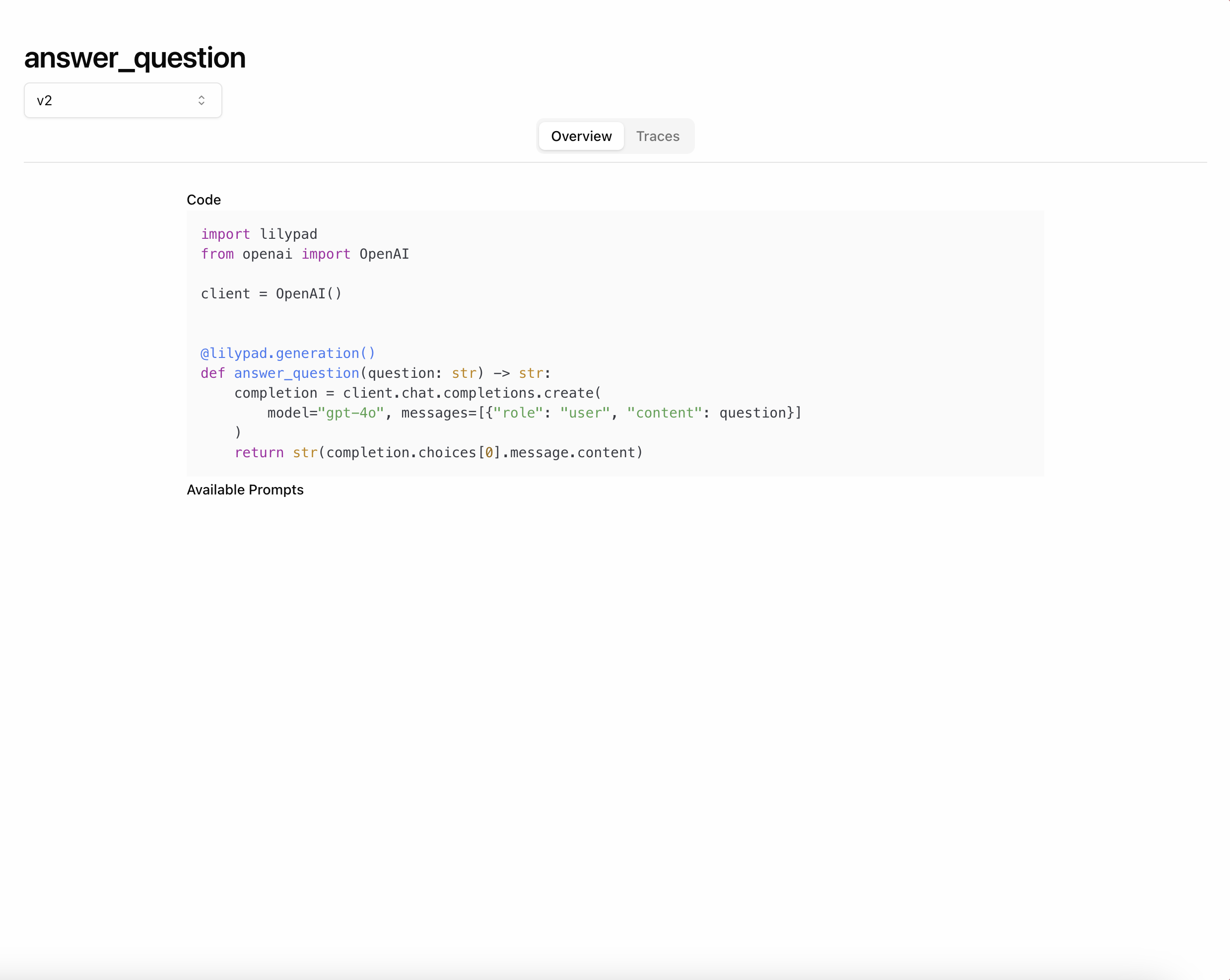
Notice that the version has changed to v2 after changing the model.
Since Lilypad versions generations using their function closure, this means that even changes to functions or classes used within the generation are automatically tracked and versioned (so long as they are user-defined).
Best Practices
Generations are non-deterministic and must be optimized. this means that they should be structured with such optimization in mind.
You can think of a generation as a simple machine learning model where the model’s input is the generations’s arguments, and the model’s output is the generations’s final return value. We use this analogy as the basis for the following best practices:
Single LLM Call Per Generation
Every call made to an LLM is non-deterministic and must be evaluated and optimized. This means that you should structure your generations to make at most one call to an LLM.
Consider the following code:
import lilypad
from openai import OpenAI
client = OpenAI()
@lilypad.generation()
def recommend_author(genre: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Recommend a {genre} author"}],
)
return str(completion.choices[0].message.content)
@lilypad.generation()
def recommend_book(genre: str, author: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Recommend a {genre} book by {author}"}],
)
return str(completion.choices[0].message.content)
genre = "fantasy"
author = recommend_author(genre)
book = recommend_book(genre, author)In the “Good” example, recommend_author and recommend_book are written as separate generations, each making a single call to the LLM.
This structure enables:
- Evaluating the
recommend_authorgeneration individually - Evaluating the
recommend_bookgeneration individually - Evaluating both together by supplying
recommend_bookwith an actual output fromrecommend_author
In the “Bad” example, the recommend_author functionality is instead written inside of recommend_book.
This makes evaluating the quality of the recommend_book generation significantly more difficult and eliminated the possibility of evaluating recommend_author.
Structure Multiple Steps According To Versioning
Generally when running multi-step generations, we recommend connecting the steps inside of a non-generation function. For example:
import lilypad
from openai import OpenAI
client = OpenAI()
@lilypad.generation()
def recommend_author(genre: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Recommend a {genre} author"}],
)
return str(completion.choices[0].message.content)
@lilypad.generation()
def recommend_book(genre: str, author: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Recommend a {genre} book by {author}"}],
)
return str(completion.choices[0].message.content)
def recommend_book_chain(genre: str) -> str:
author = recommend_author(genre)
return recommend_book(genre, author)
genre = "fantasy"
book = recommend_book_chain(genre)This sticks to the “Single LLM Call Per Generation” best practice and allows for easy evaluation of both recommend_author and recommend_book individually.
However, there are some cases where the entire chain should be versioned and evaluated together. In such a case, you can chain generations inside of a generation function.
For example, we could call recommend_author inside of recommend_book to ensure that changes to recommend_author impact the version of recommend_book.
import lilypad
from openai import OpenAI
client = OpenAI()
@lilypad.generation()
def recommend_author(genre: str) -> str:
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Recommend a {genre} author"}],
)
return str(completion.choices[0].message.content)
@lilypad.generation()
def recommend_book(genre: str) -> str:
author = recommend_author(genre)
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Recommend a {genre} book by {author}"}],
)
return str(completion.choices[0].message.content)
genre = "fantasy"
book = recommend_book(genre)It’s up to you to determine which structure best suits your use-case.
Jsonable Arguments
Although not required, we highly recommend making sure that input arguments to your generations are JSON serializable. This makes it possible to generate synthetic data for generations based on the function signature.
We have some features in the works for this type of generation, so it’s a good idea to use JSON serializable arguments to be able to best take advantage of these upcoming features.
For example, we would recommend passing in a Literal or Enum type and selecting an object from that argument rather than directly passing in the argument:
from typing import Literal
from anthropic import Anthropic
import lilypad
from openai import OpenAI
openai_client = OpenAI()
anthropic_client = Anthropic()
@lilypad.generation()
def recommend_book(genre: str, provider: Literal["openai", "anthropic"]) -> str:
if provider == "openai":
completion = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Recommend a {genre} book"}],
)
return str(completion.choices[0].message.content)
else:
message = anthropic_client.messages.create(
model="claude-3-5-sonnet-latest",
messages=[{"role": "user", "content": f"Recommend a {genre} book"}],
)
block = message.content[0]
return block.text if block.type == "text" else ""In the “Bad” example, the client argument is not JSON serializable, which makes it difficult to generate synthetic data for the recommend_book generation.
In the “Good” example, the provider argument is JSON serializable, which makes it easy to generate synthetic data for the recommend_book generation.